
SEDA (Speech Enhancement using Decomposition Approach)
Babble Noise Reduction
SEDA is a new wavelet-based algorithm to enhance the quality of speech corrupted by multi-talker babble noise.
The algorithm comprises three stages:
A significant improvement in intelligibility and quality was observed in evaluation tests of the algorithm with cochlear implant users. Furthermore, subjects rated the sound quality of speech in babble as better with SEDA noise reduction than without SEDA noise reduction.
Details on an early version are published in:
Soleymani, R., Selesnick, I. W., and Landsberger, D. M. (2017). "SEDA: A tunable Q-factor wavelet-based noise reduction algorithm for multi-talker babble," Speech Communication. pdf
The algorithm comprises three stages:
- The first stage classifies short frames of the noisy speech as speech-dominated or noise-dominated. We design this classifier specifically for multi-talker babble noise.
- The second stage performs preliminary de-nosing of noisy speech frames using oversampled wavelet transforms and parallel group thresholding.
- The final stage performs further denoising by attenuating residual high frequency components in the signal produced by the second stage.
A significant improvement in intelligibility and quality was observed in evaluation tests of the algorithm with cochlear implant users. Furthermore, subjects rated the sound quality of speech in babble as better with SEDA noise reduction than without SEDA noise reduction.
Details on an early version are published in:
Soleymani, R., Selesnick, I. W., and Landsberger, D. M. (2017). "SEDA: A tunable Q-factor wavelet-based noise reduction algorithm for multi-talker babble," Speech Communication. pdf
Above: Video Demo of the First iOS SEDA Prototype |
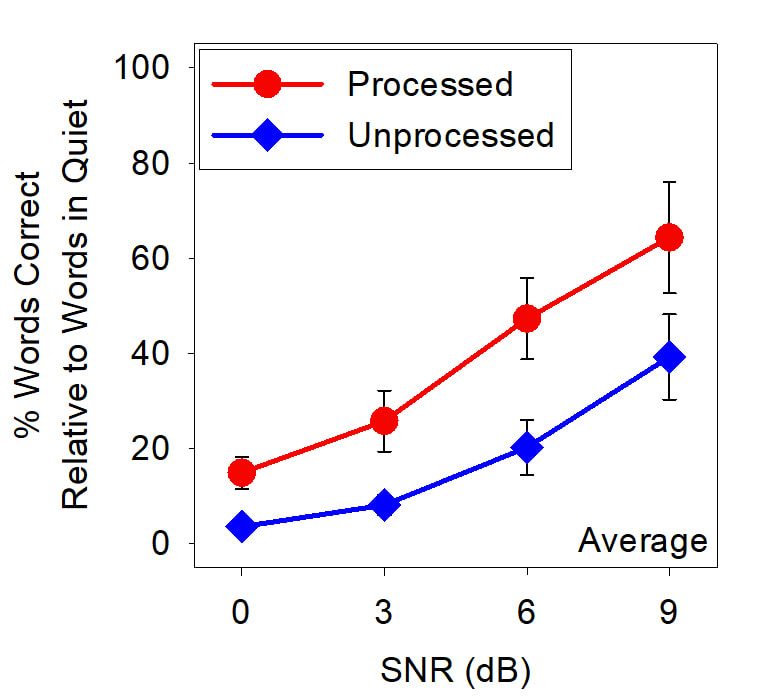
Speech intelligibility of IEEE sentences in multi-talker babble with (blue) and without (red) SEDA processing averaged across 7 cochlear implant users. The purple dashed line indicates performance for the subject in quiet, representing the best possible score for that subject. Note that this data was collected with an earlier version that pre-processed the audio signal. We are presently evaluating the real-time implementation with cochlear implant users.
|

Bab-El: An Android App for Babble Reduction
Bab-El is a prototype babble noise reduction app which works on Android cellphones and tablets which is designed based on SEDA algorithm. The current version of the Bab-El can run in real-time on most Android devices and introduces a latency as low as 20 milliseconds.

ALTIS
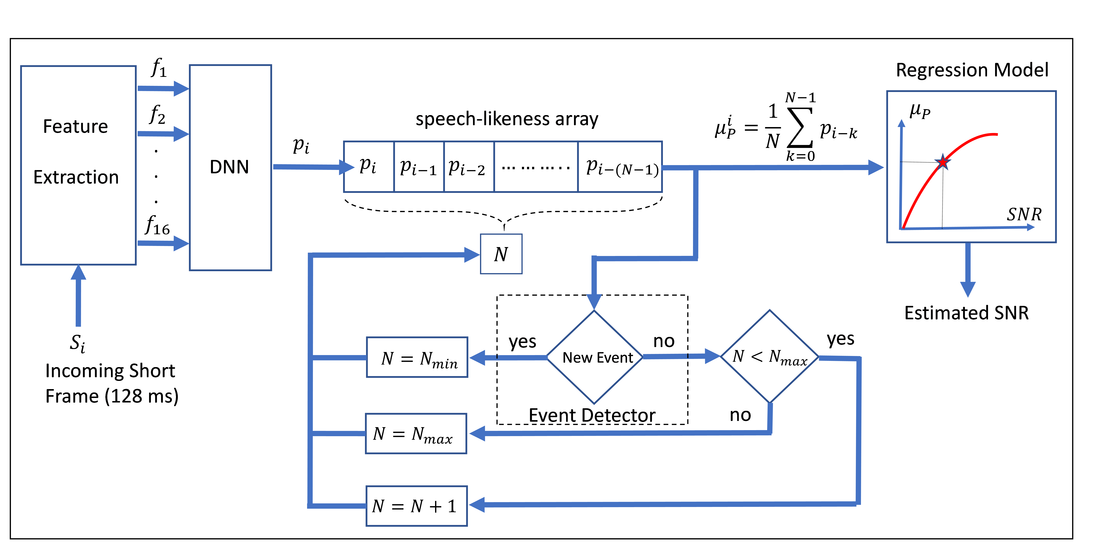
Signal-to-Noise Ratio (SNR) estimation is an important component of many speech processing algorithms. Most previous works have focused on instantaneous short-term SNR which is estimated over short-frames of the noisy speech. Other algorithms have been developed to estimate the overall SNR which is estimated over the entire length of the noisy speech. We introduce an instantaneous long-term SNR estimation algorithm which estimates the acoustically perceivable long-term noise level in the noisy speech. The instantaneous long-term SNR is estimated by averaging the “speech-likeness” values of multiple consecutive short-frames of the noisy speech over an adaptive long-frame. The algorithm is calibrated to be insensitive to transient changes in speech or noise level. However, it quickly responds to non-transient changes in instantaneous SNR by adjusting the duration of the long-frame on which the long-term SNR is measured. The algorithm was trained and tested for randomly generated speech samples corrupted with multi-talker babble. In addition to its ability to provide an instantaneous long-term SNR estimation in a dynamic noisy situation, the evaluation results show that the algorithm outperforms the existing overall SNR estimation methods in multi-talker babble over a wide range of number of talkers and SNRs. The relatively low computational cost and the ability to update the estimated long-term SNR several times per second make this algorithm capable of operating in real-time speech processing applications.
SWEDA
SEWDA is a new three-stage algorithm with the goal of improving intelligibility of speech in the presence of background noise (including multi-talker babble) is introduced. The first stage determines the noise level in the noisy speech. The second stage de-noises and decomposes the speech signal into two components: a low Q-factor component and a high Q-factor component. The high Q-factor component has more sustained oscillatory behavior than the low Q-factor component. This signal decomposition/de-noising is achieved using a sparse optimization wavelet method. The third stage performs spectral cleaning of the signal using the information obtained from the aggressively de-noised low Q-factor and high Q-factor components. Listening tests have been conducted with seven cochlear implant users. For all subjects, intelligibility and sound quality improved. However, the improvement varied across subjects, signal-to-noise ratios and number of talkers in the babble.
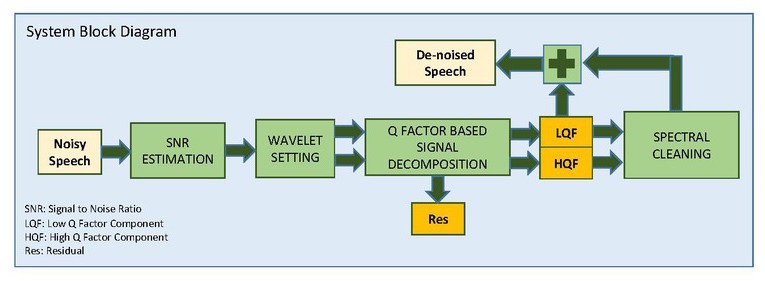
Block diagram of the SWEDA algorithm. The three stages described in the text have color coded backgrounds. Stage 1: SNR Estimation (green). Stage 2: Signal decomposition and initial de-noising (yellow). Stage 3: Spectral cleaning and re-composition (blue). Abbreviations: Signal to Noise Ratio (SNR), Residual (RES), Low Q-factor (LQF), and High Q-factor (HQF).
Poster from ARO MidWinter Meeting 2016:
Soleymani, R., Selesnick, I., and Landsberger, D.M. (2016) “Evaluating a New Algorithm for Multi-Talker Babble Noise Reduction Using Q-Factor Based Signal Decomposition” in ARO Midwinter Meeting (San Diego, CA).
Press Links:
NYU Press Release
Advance Healthcare for Speech and Hearing
DZone Internet of Things
Yahoo
Soleymani, R., Selesnick, I., and Landsberger, D.M. (2016) “Evaluating a New Algorithm for Multi-Talker Babble Noise Reduction Using Q-Factor Based Signal Decomposition” in ARO Midwinter Meeting (San Diego, CA).
Press Links:
NYU Press Release
Advance Healthcare for Speech and Hearing
DZone Internet of Things
Yahoo