
 Monica represented the EAR Lab at the Long Beach, CA Walk4Hearing on Saturday, June 11th. It was an unusually cold day, with lots of people including myself amazed at the California rain (drizzle) showing up. Since last year, the route has changed to go around the beachfront, making it a little more challenging. Instead of walking around the shops, the walk covers a really nice path along the ocean. Walk4Hearings around the country are chosen to represent the best of the local area; a path along the ocean is perfect to represent southern California.  Plenty of food, snacks and drinks for everybody were provided at the beginning and the end of the walk. Many companies and organizations were there to show support.
People of all ages and families supporting their loved ones were present, because hearing loss can affect anybody at any age. The Walk4Hearing is the most important fundraising event for the Hearing Loss Association of America (HLAA). The HLAA of course is an important cause near and dear to our hearts at EAR Lab. Additionally, for the EAR Lab, the Walk4Hearing is an excellent chance to catch up with people we have known for several years and a chance to meet some amazing new people. Monica is already looking forward to next year’s Long Beach walk. A bunch of Walk4Hearing events will take place in other parts of the country in the Fall.
0 Comments
Jacob Taylor has just officially joined the EAR Lab. He is here for the summer to learn more about the world of cochlear implants and auditory science. We are very happy to have him as part of the team. Below is a brief bio of Jacob. If you want to know more about other members of the team, click here.  Jacob Taylor is an undergraduate student at Southwestern University working in the EAR Lab for the summer. He will graduate with a Bachelor of Arts in Biology in the Fall of 2017. He intends to pursue a career in auditory research and is presently investigating if a Ph.D or Au.D. is the appropriate path for his career interests. He is primarily interested in studying how inner hair cells convey information as well as improving sound coding in cochlear implants.
 Josh giving a talk at EAR Lab Josh giving a talk at EAR Lab Josh Stohl of MED-EL is visiting us for two days. We've both been working on similar experiments on pitch with cochlear implants. So the plan is to compare notes and see if two heads are better than one. Last week Stefan Brill came by as well to check out what's happening here at NYU. He drove from Toronto to New York on his way to North Carolina. Unfortunately we didn't get a photo of him presenting here. So we asked him to take a selfie in NC with Josh. The photo he sent us was particularly cool! Stefan (left) and Josh (right) are holding up the original CIS processor built by Blake Wilson for Inneraid patients for the famous Nature paper: Wilson, B.S., Finley, C.C., Lawson, D.T., Wolford, R.D., Eddington, D.K., and Rabinowitz, W.M. (1991). Better speech recognition with cochlear implants. Nature. 352, 236-238. pdf  Stefan Brill (left) and Josh Stohl (right) showing off Blake Wilson's original CIS processor  Thanks for the photo, Justin Aronoff.
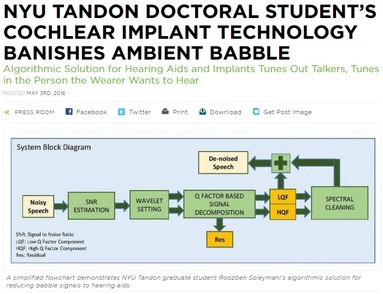 Full press release can be seen here:
http://engineering.nyu.edu/press-releases/2016/05/03/nyu-tandon-doctoral-students-cochlear-implant-technology-banishes-babble Wearers of cochlear implants and hearing aids often have difficulty teasing out what someone is saying over “babble” — the cacophony of other talkers — and other ambient sounds. New York University researchers have devised a novel solution: an algorithmic approach that, like making drinkable water from pond water, distills the talker’s voice from a turbid wash of noise. Most algorithms for acoustic noise suppression aim to eliminate steady background noise — the sound of an air conditioner or road noise are familiar examples — which is relatively easy to attenuate. Babble is much more difficult to suppress because it resembles the foreground voice signal one aims to hear. Few algorithms even attempt to eliminate it. To tackle the problem, Roozbeh Soleymani, an electrical engineering doctoral student, created an innovative noise reduction technology called SEDA (for Speech Enhancement using Decomposition Approach) with Professors Ivan Selesnick and David Landsberger in the NYU Tandon Department of Electrical and Computer Engineering and the NYU Langone Department of Otolaryngology, respectively. The traditional method to analyze a speech signal decomposes the signal into distinct frequency bands, like a prism that separates sunlight into a rainbow of colors. SEDA, however, decomposes a speech signal into waveforms that differ not just in frequency (the number of oscillations per second) but also in how many oscillations each wave contains. “Some waveforms in the SEDA process comprise many oscillations while other comprise just one,” said Selesnick, whose National Science Foundation-funded research in 2010 was the springboard for Soleymani’s work. “Waveforms with few oscillations are less sensitive to babble, and SEDA is based on this underlying principle,” said Soleymani. Selesnick added that this powerful signal analysis method is practical only now because of the computational power available in electronic devices today. J. Thomas Roland, Jr., the Mendik Foundation Professor and chairman of the Department of Otolaryngology-Head and Neck Surgery at NYU Langone, said noise is the number-one problem for people with any degree of hearing loss, even with an appropriately fit hearing aid or cochlear implant. “It is also a big problem even for normal-hearing people,” he said. The potential uses for SEDA, for which a U.S. patent application has been submitted, go way beyond helping the hearing impaired. “While it was originally conceived for improving performance with cochlear implants (which it does very well), I can imagine the market might even be bigger in a mobile phone arena,” said Landsberger. Outside funding support was provided by the National Institutes of Health’s National Institute on Deafness and Other Communication Disorders. |
EAR LabThis is where we provide updates from the lab Archives
December 2018
Categories |


 RSS Feed
RSS Feed